 Science Explorer
Science Explorer
SciX Data Linking and Indexing part III. Cited data
Edwin Henneken (Content Curation & Collaborations Lead)
01 Aug 2024
Introduction
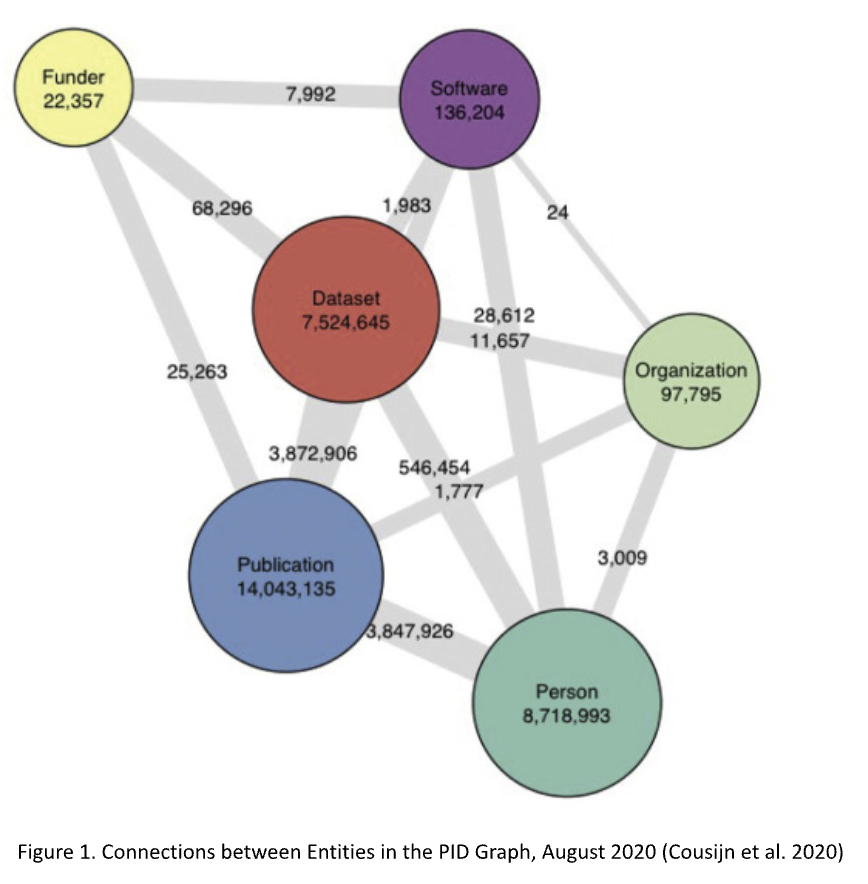
This blog is the final part in the series on data linking and indexing in the Science Explorer (SciX). In the first part we provided a general overview of the holdings in SciX, and the second part discussed the role and merits of linked data in this service. In this part we do something similar for cited data products. There is no fundamental difference between articles citing other articles (something which we have been recording for decades) and articles citing data; actually, the “cites” relationship can be between any bibliographic asset. Citations are just one small subset of the entire graph of linkages between research assets; if we add the constraint that all these research assets must have a persistent identifier (PID), this graph is also referred to as the PID graph. A citation graph is a special case of a PID graph. Figure 1 illustrates the PID graph as generated by project FREYA in August 2020 (Cousijn et al. 2020).
Cited data products
As mentioned in part I, citations can only be assigned within SciX when the cited work has a corresponding SciX record as well; in other words it has to be “indexed” in the system. In order to be able to index a record, a minimum amount of metadata of sufficient quality has to be available. Most of the indexed content in SciX consists of literature records, but a significant and fairly recent addition to our collection consists of records representing data and software. Software is truly a recent addition, but records representing data products were first introduced quite a while ago. As early as 1995 records were indexed for the data catalogs maintained by the VizieR database at CDS. In the early 2000s observing proposals were added for a number of NASA missions and observatories. A decade ago we included NASA Astrophysics grant funding proposals. In addition to these sources we are also systematically indexing records for datasets in the Planetary Data System (PDS) and datasets of the Japan Aerospace Exploration Agency (JAXA).
SciX is a publication-centric discovery platform, so it supports the discovery of research artifacts as they are linked to the scholarly literature. This informs the strategy for indexing data products: with exception of a certain class of data products, we will only index those that are formally cited in the scholarly literature. While true in principle, this statement needs to be made more explicit and nuanced. For one, we need to specify what we mean by a “certain class”. The nuance is needed for the “formally cited” part.
The “certain class” criterion relates to the fact that not all data products are created equal. There is a type of data product that is usually referred to as a “high-level science product”, or a “curated dataset”. These data products are almost like publications; in general they go through an extensive reviewing and curation process. It is this class of data products we have in mind for the “certain class” criterion for indexing. The aforementioned PDS datasets are an example of these curated data products. It is not uncommon for high-level science products to be accompanied by data publications: articles in refereed journals describing the data in detail. Often data centers and data authors prefer these articles to be cited, rather than the data product itself. This is typically done by including in a data product landing page a “cite as” statement recommending that a paper citation be used instead. However, reality has shown that these statements are not always followed. It is not clear whether this is the result of an author ignoring this statement or some information being lost during the journal’s copy-editing process. Having said this, the official SciX point of view is that when a data paper is available, both the paper and the dataset should be cited; just like with software papers, data papers are insufficient proxies for a particular dataset. The data paper should be included as citation for background information and attribution, while the dataset should be cited separately to support reproducibility and discoverability.
Besides these high-level data products there is a very long tail of custom data products; they are mostly those that were made to support a particular publication. Some data centers support the creation of data bundles based on the selection of parts of larger datasets, often supporting the creation of a DOI for this custom bundle. Creating records for these as they get cited would result in opening the floodgates for indexed data products in SciX. Clearly, that would not be a desirable outcome. This is the part where we need to nuance the indexing criterion. This nuance will come in the form of a “reuse criterion”: only when a data product is cited a second time will a record be created. Figure 2 gives an indication of what to expect: it shows the citation count as a function of publication year for dataset records in NASA SciX. These are not the actual counts, currently in the system, but the estimated ones if we were to create a record for every cited DOI corresponding to a dataset. The actual counts are likely to be even higher.
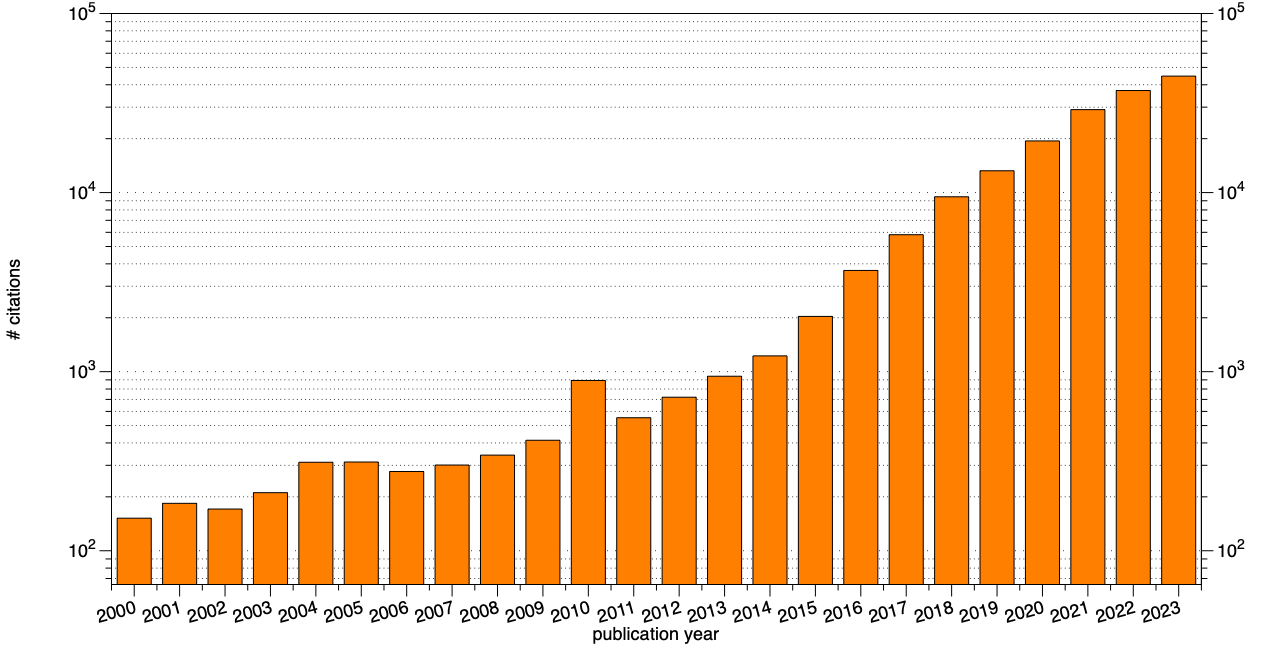
Figure 2. Estimated citation count as a function of publication year for dataset records in SciX
In total, there are about 179k of these datasets, but only 19k were cited more than once.
That leaves one last matter: the minimal metadata required and metadata quality. To support discoverability, a record needs a minimal set of attributes and these attributes need to be meaningful to a wider audience than just the creators of the data. Software records indexed from Zenodo offer some examples of the challenges: some author names are just represented by their Github handles and some records do not have an abstract, just a nondescript title.
This minimal set of desired attributes for software and data products is the following:
- Title
- Authors
- Abstract
- Publication date
- Link to the data
Ideally, having keywords would be great too, especially if they come from a controlled vocabulary or ontology (like the Unified Astronomy Thesaurus). Metadata quality is harder to check; clearly we do not do this for software records.
We can summarize the acceptance criteria for indexing data products as follows:
- If the citation found is for a dataset already indexed in SciX: assign the new citation
- If the citation found is new and for a high-level/curated dataset: create record & assign citation
- If the dataset was cited for a second time: create record & assign both citations
The third criterion is to prevent the floodgates effect, mentioned earlier.
As said earlier, the statement “publication contains a link to a dataset in the reference section” has a specific meaning: the citation must use the DOI of the data product. The simple reason is that any other URIs are not actionable because they do not have metadata associated with them that can be retrieved from a registry; given a DOI, all metadata can be harvested automatically from the repository where the DOI was registered.
Working with cited data in SciX
Once data products are indexed, a range of new discovery possibilities become possible. It depends on the target audience to what extent these possibilities are interesting or useful. On one end of the spectrum one could explore the context of a single data product, while on the other end, one can do this for a larger collection, e.g. all data products indexed for one repository. Indexed data products can also be grouped by other criteria, naturally.
Below is a set of questions that be answered for data product records that are indexed:
- In what context is my data being used?
- In what (Open Access) publication venues is my data being cited?
- Where do researchers work who cite my data?
- What are the citation and usage metrics for my data?
Questions like these are relevant for individual researchers, but also for data, repository and mission managers. For archival data it will be particularly useful and interesting to use the scholarly network to see the impact it is having and whether it is being used as a stepping stone (Peek et al. 2019). It will also allow the study of trends in Open Science.
Before going into the specifics of these questions, we will first show some of the more general queries to discover and interact with indexed data products (see table 2).
| Question | SciX query |
|---|---|
| Find all data product records | doctype:dataset |
| Find all records for data repository with DOI prefix 10.26033 | doi:”10.26033/”* |
| Find all records for data repository with DOI prefix 10.26033 with citations | * doi:”10.26033/” has:citation_count |
| Find all data products with a specific publication abbreviation (bibstem) | bibstem:yCat |
| Find all data records that do not have a link to data | doctype:dataset -property:data |
| Find all records with a link to the PDS data archive | data:PDS |
Table 1: general queries for discovering indexed data products
To illustrate finding answers to questions about individual data products, we look at the following record already indexed in SciX: “The IVS data input to ITRF2014”, published by GFZ Data Services, Helmoltz Centre, Potsdam, Germany. As of April 11 it has 46 citations. On the one hand, this dataset is relevant to VLBI observation, while on the other, it is relevant to geodesy, specifically to the International Terrestrial Reference System (ITRF). Is this reflected in the context of those 46 citations? The results in figure 3 (created using the SciX paper network) highlight that some of them relate to astrometry, while others focus on the pure geodesy part. The Publications facet shows a wide range in publication venues. Adding the filter property:openaccess shows that about 50% of the citing works are Open Access. Since this data product comes with rich metadata, a useful venue for further discovery could be the use of the similar() operator; based on textual similarity, what other records in NASA SciX could potentially be interesting if this data product is relevant to your research? Executing the query similar(bibcode:2015ivs..data….1N) returns an extensive list of publications, many about VLBI, but also with wider geodesy applications. A narrower version of this query also returns interesting results: what data products or software records are similar to this data product? The query similar(bibcode:2015ivs..data….1N) doctype:(dataset OR software) will return these results. Naturally, many VizieR data catalogs are returned, but also a software records like “SOFA: Standards of Fundamental Astronomy” and “liulei/volks: VOLKS: VLBI Observation for the Localization of frb Keen Searcher”.
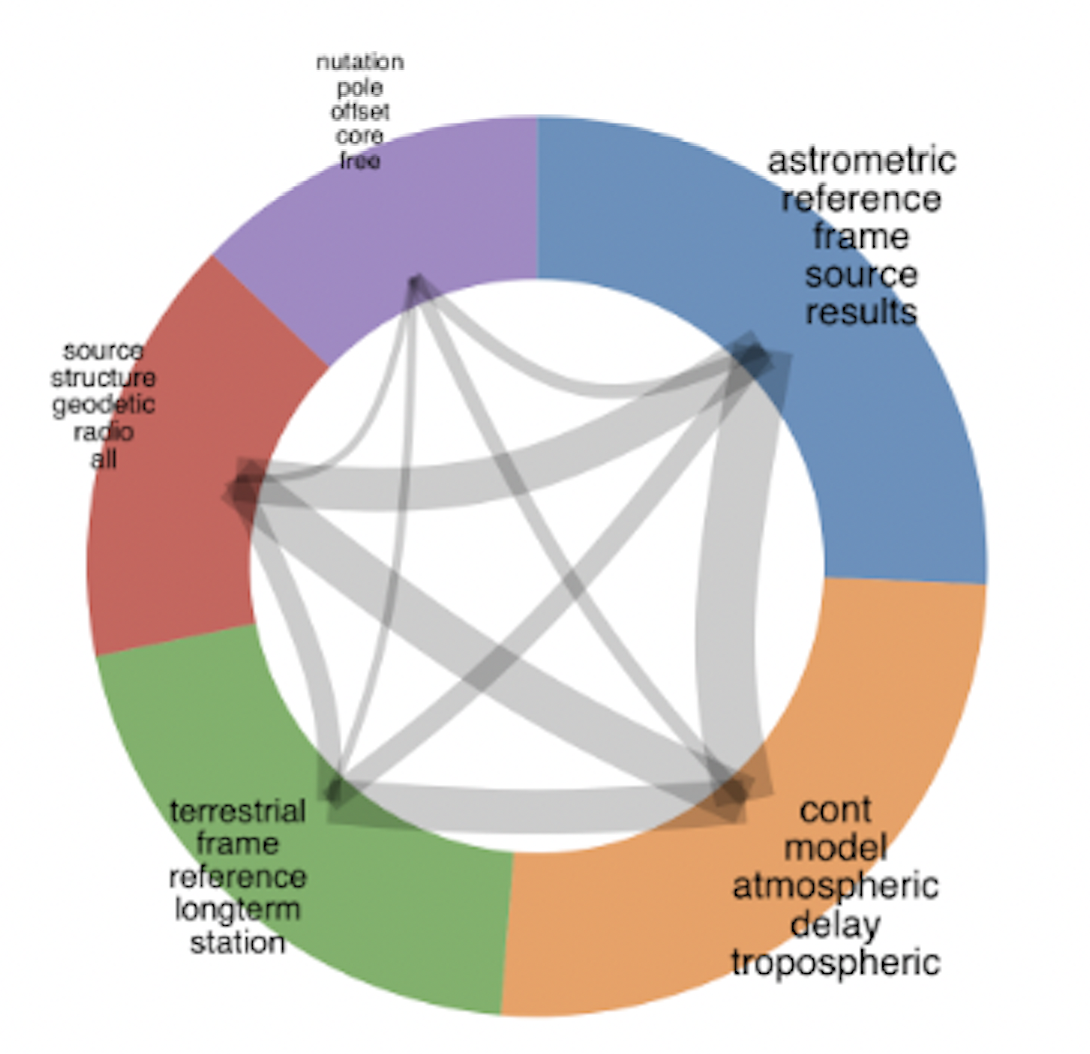
Figure 3. Paper network for the publications citing the data product "The IVS data input to ITRF2014"
The collection of indexed data products that is the most suitable to use as an example is that of VizieR data catalogs. In total there are currently 20,432 of these records with 10,361 total citations. VizieR provides the most complete library of published astronomical catalogs (tables and associated data) with verified and enriched data. Given the size of this collection and the limitations of the available analysis tools within SciX, we will explore a subset of these records.
Focusing on the 5,000 most recent VizieR data catalogs, we discover that they have been cited by just under 800 publications; close to 600 of these are Open Access publications with links to data. Figure 4 illustrates the range of topics covered by these publications by creating the Paper Network. The Publications facet for these citations shows that they mostly come from the well-known astronomy publication venues and the Institutions facet (see figure 4, right) indicates that the authors of the citing publications work at a wide range of locations. The citing publications are also represented in many bibliographic groups (“bibgroups”); these are curated lists of publications for institutes, missions or instruments.
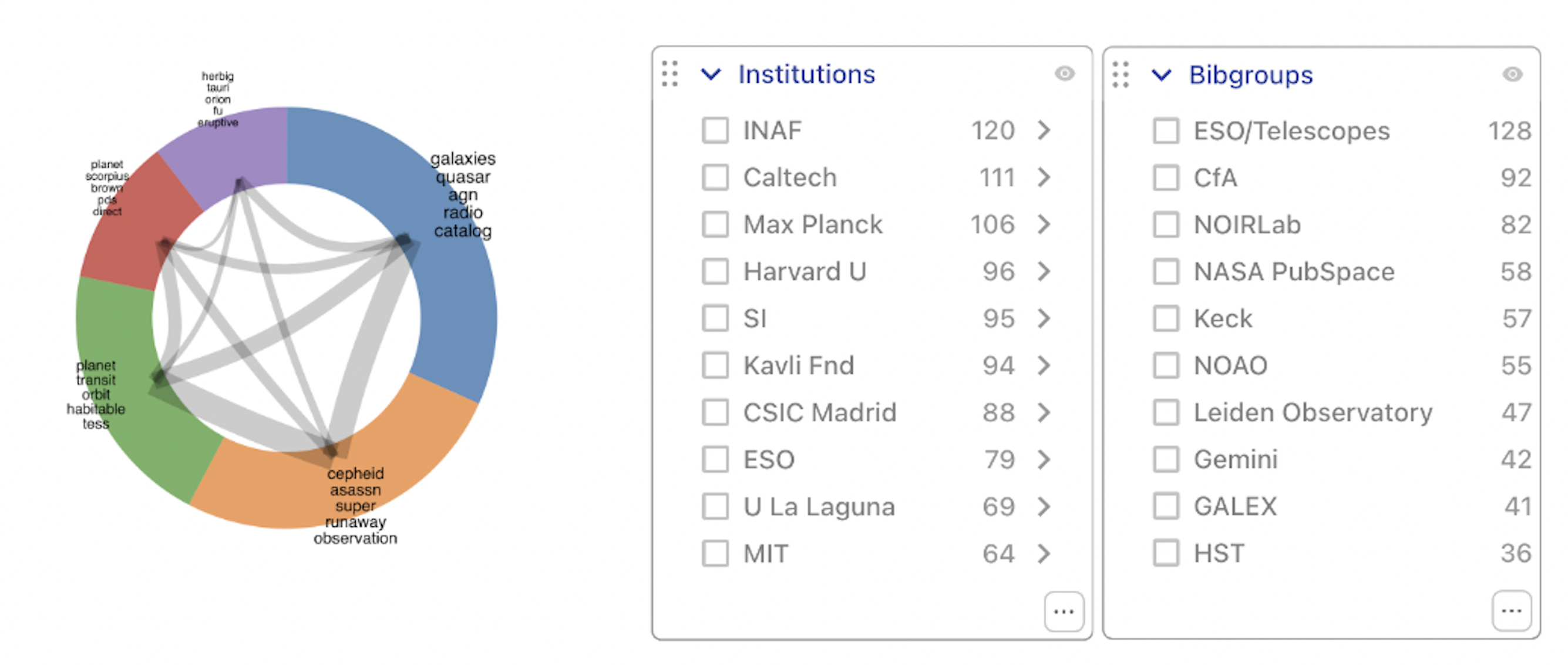
Figure 4. Left: Paper network for the publications citing the top 5000 most recent VizieR data catalogs. Right: Institutions and Bibgroups facets for the publications citing the top 5000 most recent VizieR data catalogs.
Concluding remarks
In summary, what is currently being supported in SciX in regards to the linking to and indexing of data products?
Data linking
- Data links provided by collaborators and external curators are actively added
- Data links are mined from full text provided by publishers known to support discoverable data links
- Data links are not indexed directly in SciX
Data indexing
- Systematic indexing of data products for a few sources
In the near future, we plan to implement the following in addition:
Data linking
- Data product DOIs found in bibliographies will be used to create data links
Data indexing
- Cited, high-level, curated data products will be indexed Re-used data products will be indexed
Naturally, when data products get indexed, any citations for them will get attributed to them.
With all of this in place, we will be able to say that SciX contains accurate representations of research life cycle products. Besides the scholarly publications, SciX will have records for conference proceedings and abstracts, proposals, software and data products, in addition to links to data. Next, we will be focussing on indexing grant funding information with the help of the publishers and organizations like Crossref and CHORUS, and the indispensable support of institutional and organizational librarians.
Questions or feedback? Contact us at help@scixplorer.org.