 Science Explorer
Science Explorer
ADS Docmatcher
Jennifer Koch, Golnaz Shapurian, Carolyn Grant, and Donna Thompson (ADS)
28 Sep 2022
The primary aim of the Docmatcher pipeline is to match arXiv preprints to the peer-reviewed published version, and vice versa. ADS previously used the ADS Classic ingest system to accomplish this, however with recent updates and developments to the ADS Solr search engine, it has become a high priority to migrate Classic processes to use Solr and eliminate Classic dependencies. Therefore, the ADS team has made new updates, tests, and implementations for this new version of the ADS Docmatcher.
Background & arXiv Relationship
ADS regularly retrieves data from arXiv, a free distribution service and open-access archive for scholarly articles. Members in the scientific community generally share preprint or e-prints of their work on arXiv before and during the peer review and publication process with a scholarly publisher. arXiv began its service in 1991, at roughly the same time that ADS was beginning to launch its database of astrophysical abstracts. Early on, ADS collaborated with arXiv to retrieve and index e-prints, to enable access to papers weeks or months before their official publication.
ArXiv releases data five times per week, and lately has averaged about 15k manuscripts per month, which makes about 700 manuscripts per release! Therefore, ADS indexes arXiv articles nightly, five times per week, via an Open Archives Initiative (OAI) harvest, and tries to match incoming articles to those already in ADS. In addition, at the end of ADS weekly physics and astronomy collection updates, an attempt is made to match all new peer-reviewed published papers to unmatched arXiv papers.
Purpose & Benefits
With so many preprints being released by arXiv, it is necessary that ADS process this content and match papers for the following reasons.
ADS Goals:
- We aim to ingest new records for content relevant to ADS collections in order to expand coverage of the scientific literature.
- We aim to keep ADS collections updated with the peer-reviewed versions that are published, so that users have the most accurate, up-to-date information possible.
Benefits:
- Improves citations and metrics, and eliminates double counting of a single scholarly work (preprint + published versions).
- Users benefit from this merge: authors prefer their published papers to be cited rather than their preprint.
- Users also have an opportunity to discover and obtain an open access (preprint) version for published articles that are behind a paywall.
- Publishers like this merge because they prefer researchers to use the published version of the record as the definitive source.
- For citation purposes: the matching allows ADS to capture citations made either with an arXiv ID or with publisher metadata.
Docmatching Pipeline Development
Given these goals, ADS set out to develop a new Docmatching pipeline using our current infrastructure: our Oracle matching service and the Solr search engine.
Problem: Given text and metadata (DOI, abstract, title, authors, year) of an input record, find a matching record that exists in ADS. If the record is an arXiv paper, the match has to be a publisher record and the other way around.
Solution: Docmatcher utilizes ADS API services following these steps:
- Docmatcher is given a set of metadata (DOI, abstract, title, authors, year) for a paper, arXiv or otherwise, and sends it to the Oracle Service for matching.
- Oracle queries the Solr search engine with the DOI as available, otherwise the abstract, otherwise the title.
- Oracle computes the similarity between the input record and the resulting record(s) returned from Solr. This includes computed scores for each of the available data fields.
- Based on the similarity scores, Oracle determines if the two records are a match, and gives it a confidence score.
- Oracle sends the bibcode results to Docmatcher for curation staff to review and verify.
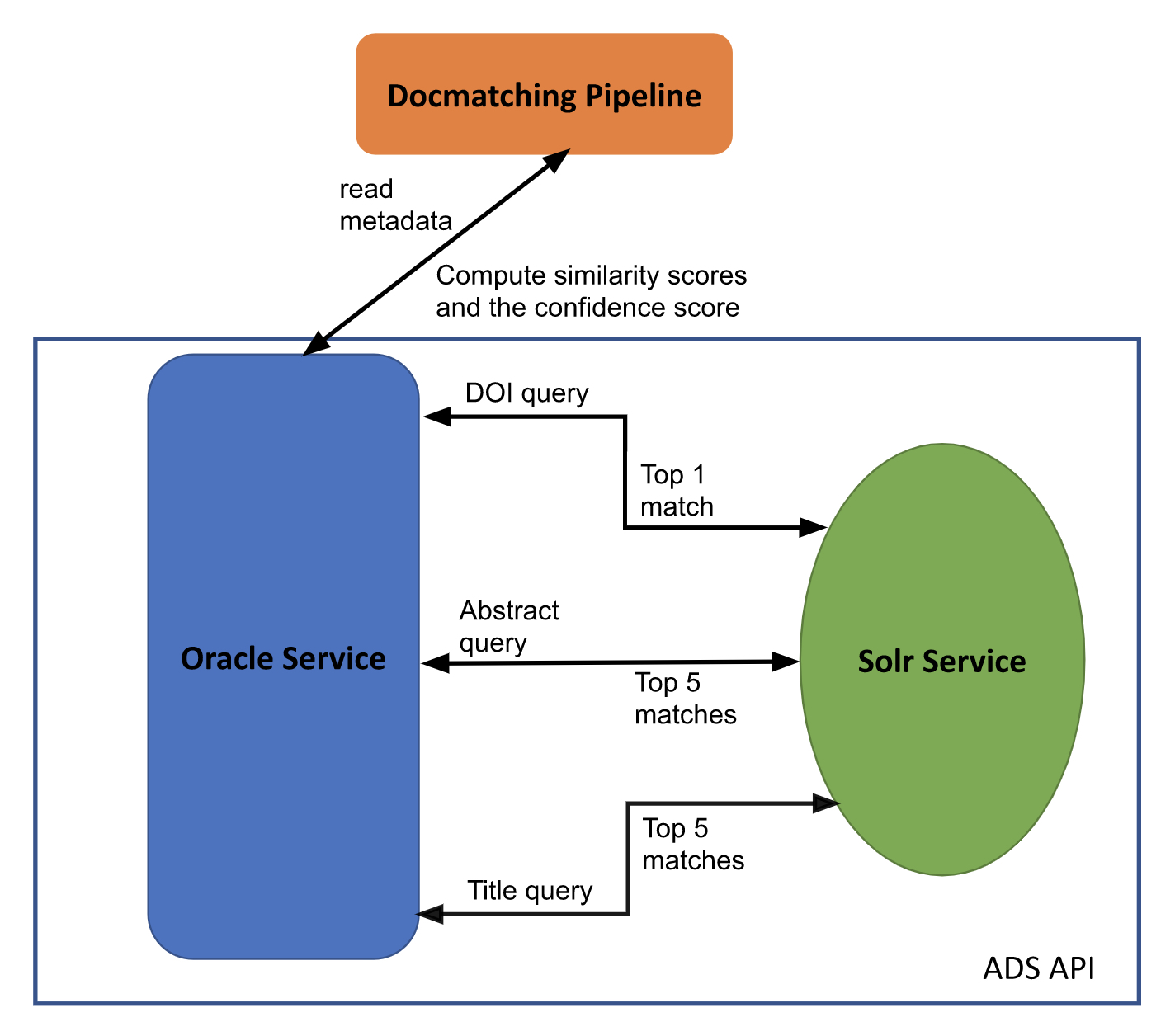 Diagram of Docmatcher Pipeline
Diagram of Docmatcher Pipeline
Score Computation Model: We trained a deep learning model for computing the similarity scores in the Oracle service, initially experimenting with the number of layers and nodes. We also considered the activation function, introducing non-linear complexities to the model. We experimented with two loss functions: binary cross-entropy (logistic regression) and MSE (linear regression). We also experimented with two optimizer functions: Adam and RMSprop. Finally, we created and evaluated models with different parameters, and we were able to identify the best model with the highest accuracy.
Testing & Verification
While refining the new computation model, we reviewed several data sets of daily docmatching results, verifying the correctness of the matches. The Docmatcher results were provided to curation staff as Google Sheets that included the following metadata: arXiv ID, Classic bibcode matched, Solr bibcode matched, Oracle’s confidence score and similarity scores, as well as Oracle’s label (Match or Not Match). We manually verified the matches to be sure that the label was correct, and also identified correct bibcodes for any false matches that were found. Combining the results of the daily manually curated docmatching results provided an initial training set with a total of 1543 matched pairs, where 696 of these pairs were a validated match and 847 were not a valid match. However, the more matches we validated, the more we were able to improve the model accuracy.
Advantages of the New Docmatcher Pipeline
The main differences between the Classic matcher and the new Docmatching pipeline is how the arXiv data and the DOI is treated, as well as confidence scoring.
The advantage of the Docmatcher using ADS API services is that it scores the similarity of abstract, title, author, year. With the Classic matcher, if there is a DOI, it takes it as a match and accepts it, which can be problematic in the infrequent case that the DOI is incorrect. Now with the new pipeline, we compute the similarity scores of the metadata fields, including the DOI, and the final match is based on the confidence score. There were several common cases where the new Docmatcher pipeline made improvements over the Classic matcher in correctly identifying matches:
- Based on the DOI provided, Docmatcher analyzes the match as a whole, not just by DOI alone.
- Docmatcher results reveal when a curation improvement is needed to make a match (fixing DOIs, titles, abstracts, etc.).
- Docmatcher recognizes the difference between a book chapter and the book itself, as the confidence scores reveal a difference in title and abstract.
- Docmatcher now stores historical match data with confidence scores in a database in the Oracle service, so that it does not match related papers that have lower scores.
The Future of Docmatcher
ADS plans to utilize Docmatcher indefinitely to fulfill the needs of scientists and bring its inherent benefits to users engaging with ADS content. Our team is currently making final validations to improve the accuracy, and the Docmatcher will be in production within the next month. Matches will be more accurate and more abundant than with the Classic version of Docmatcher. Users may find fewer duplicate records as the merging between preprints and their published versions becomes more accurate.
We will aim to improve the accuracy of the matching as the ADS curation team validates ambiguous matches, and the model gets better trained. A curation workflow is also in progress that will define the curators’ role in verifying matches and merging the match results.
Future ADS development ideas inspired by Docmatcher:
- Incorporate preprints from Earth and Space Science Open Archive (ESSOAr)
- Analyze content coverage of the digital repository hosted by the NASA Scientific and Technical Information (STI) Program, which collects scientific and technical works created or funded by NASA
- Improve records of PhD theses and/or connect to institutional repositories
- Improve matching of books from Harvard Libraries (HOLLIS)
Questions or feedback? Contact us at help@scixplorer.org.